



Imply, the real-time intelligence company, today announced general availability of Imply 3.2, which leverages the power and flexibility of Docker containers and Kubernetes orchestration to help enterprises easily deploy and manage the Imply platform on private and public cloud services, including Amazon Web Services, Google Cloud Platform, and Microsoft Azure.
Imply provides a complete real-time intelligence solution around Apache Druid, a popular open source database that delivers sub-second query response on enormous streaming datasets. Imply is ideal when instant insights are critical, such as when analyzing user behavior, risk and fraud management, supply chain events, and Internet of Things (IoT) device interactions. Imply complements Druid with an intuitive and responsive analytics UI, cloud-native deployment and management, performance monitoring, and enterprise-grade security.
“A market wave for real-time intelligence is building at the same time that enterprise cloud modernization is cresting,” said Vadim Ogievetsky, Chief Product Officer at Imply. “New cloud management features in Imply 3.2 let companies combine the power of Druid with the flexibility of the cloud for delivery of ad-hoc analytics against huge streaming data sets, regardless of whichever private or public cloud they adopt.”
Newly released cloud management functionality includes:
- Point-and-click control of the Druid cluster
- One-click cluster scale up
- Central control of versions and upgrades
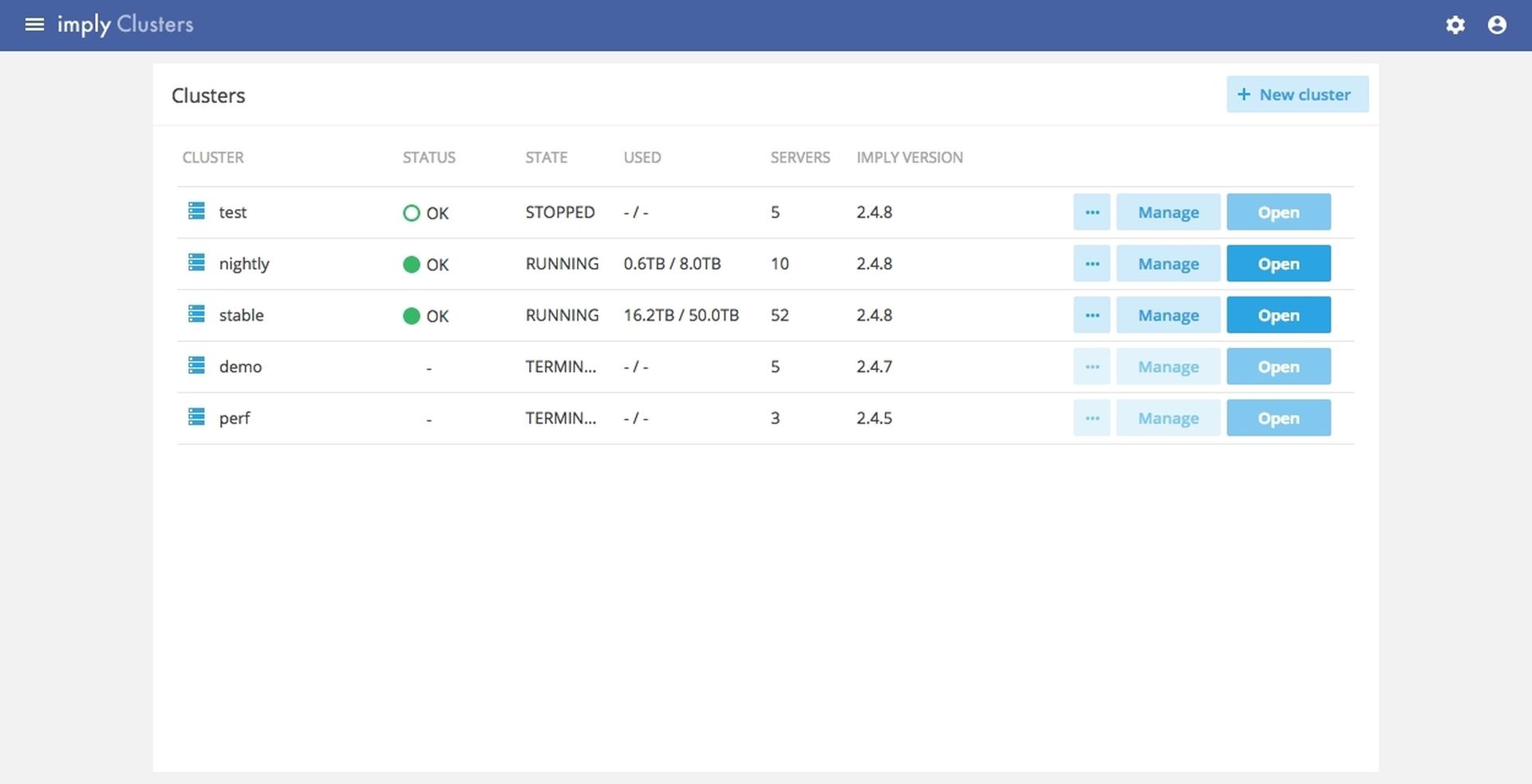 Simplifying cloud management is key to Imply’s strategy of helping companies to quickly and cost-effectively deliver the impact of real-time intelligence to both internal operational groups and customers. Other advancements in the past year include the Druid Data Loader, which replaced hand-coding of ingestion scripts with a drag and drop UI, official SQL support in Druid, and a graphical UI for building SQL queries.
Simplifying cloud management is key to Imply’s strategy of helping companies to quickly and cost-effectively deliver the impact of real-time intelligence to both internal operational groups and customers. Other advancements in the past year include the Druid Data Loader, which replaced hand-coding of ingestion scripts with a drag and drop UI, official SQL support in Druid, and a graphical UI for building SQL queries.
The Imply 3.2 release also extends source file format support and implements performance improvements, specifically:
- Direct batch ingestion from HDFS, eliminating the need for interaction with Hadoop.
- Native data ingestion support for columnar file formats ORC, Parquet and AVRO.
- Parallel merge, query vectorization and other optimizations that increases query performance 1.3X to 3X for even faster insights.

for developers and enthusiasts


{kind=link}